인공지능 구조 원리5 - 기초
어텐션의 필요성
RNN은 문장 분석 과정에 왜곡이 생긴다.
RNN은 앞 시점의 상태값이 뒤 시점으로 전달되고, 전달된 상태값과 새로운 입력값을 같이 고려해 상태값을 다시 업데이트 하는 구조다.
문제 : 입력되는 데이터가 많을수록 상태값이 갱신되는 횟수도 많아지게 된다. 이렇게 되면 앞쪽에서 입력된 데이터들, 입력 시점이 오래된 데이터들이 만들었던 상태값은 자꾸 희석돼 영향력이 낮아지는 현상이 발생한다.
EX) 지금 / 알고 / 있는 / 걸 / 그때도 / 알었더라면 / 조금 / 더 / 현명하게 / 살 / 수 / 있었을 / 텐데
- 가장 먼저 입력된 ‘지금’은 거의 잊혀 영향을 적게 미치고, 가장 최신인 ‘있었을’은 지나치게 크게 영향을 미치는 상황이 발생한다.
- 장문일수록 심하게 발생할 수밖에 없어서 인공지능 모델이 결과를 제대로 산출하는 데 장애요소가 됐고, RNN 기반 언어 모델의 고질적인 문제로 인식되고 있다.

RNN은 단어의 중요성, 단어간의 관계성 특성들을 담아낼 방법이 없다.
어텐션 메커니즘
단어 하나를 생성할 떄마다 입력 문장 전체를 다시 본다.
단어 하나하나를 생성할 때마다 매번 입력 문장의 단어 모두를 다시 검토하는 새로운 기능을 추가했다.
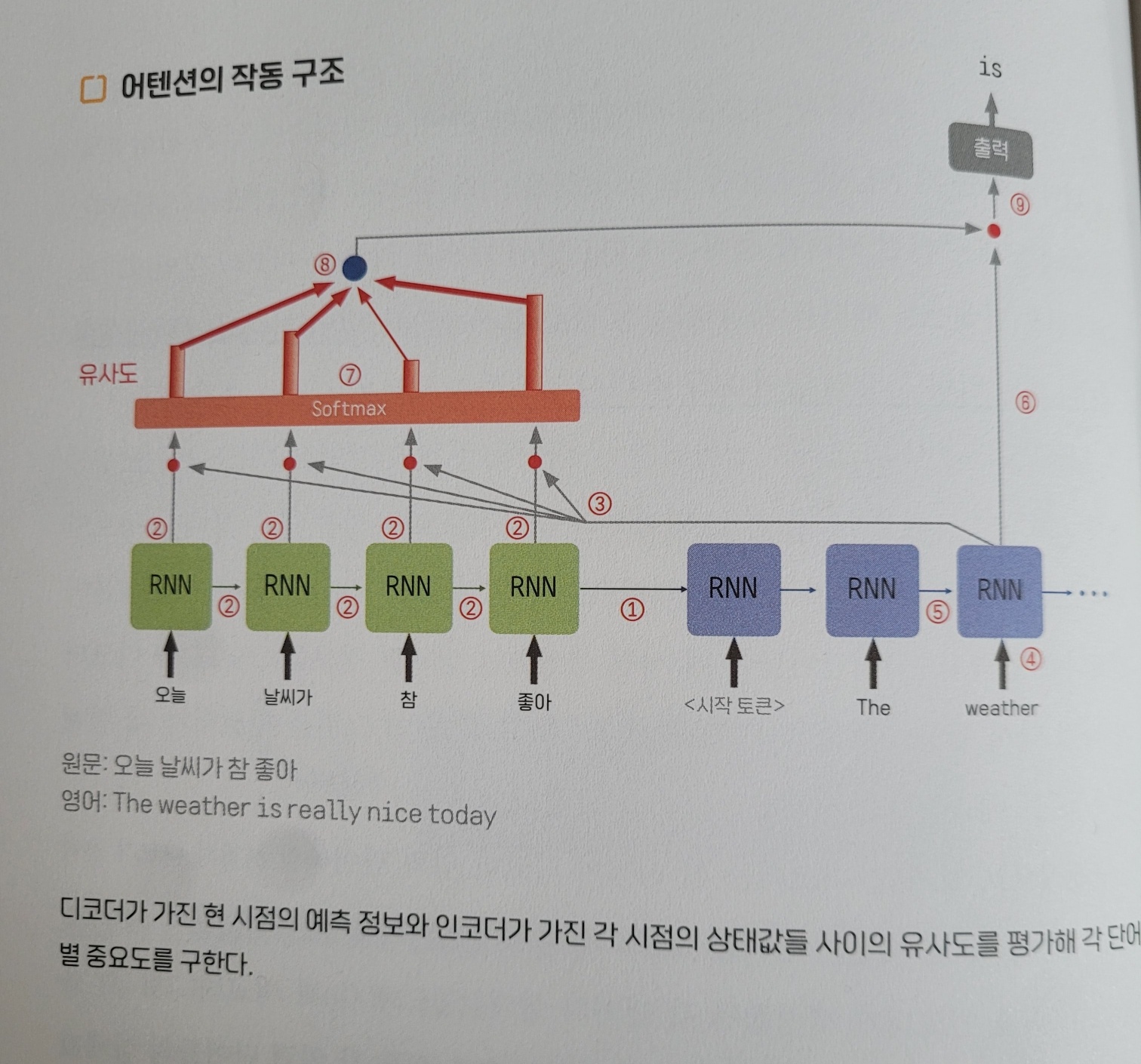
인코더에 입력되는 각 단어들이 매 시점 생성했던 상태값 정보들(2)을 디코더가 직접 다시 활용(3)하고 있는 것을 볼 수 있다.
좀 더 자세히 보자면,
- 디코더는 현 시점의 디코더 입력 단어(4)와 앞 시점의 상태값 정보(5)를 활용해 생성한 다음 단어 예측 정보(6)를 인코더가 생성했던 각 단어의 상태값들(2)과 비교해 유사성을 계산한다.
- 산출된 유사도(7)를 각 입력 단어들의 상태값에 반영해 합친(8) 하나의 종합적인 특성값을 만든다.
- 이 값(8)과 본래 갖고 있던 예측 정보(6)를 결합한 값(9)을 활용해 다음 단어를 예측한다.
디코더가 입력 문장의 단어들을 직접 ‘주목’하고 중요도에 따라 적절하게 ‘관심’을 준다 해서 이와 같은 기법을 ‘어텐션’ 기법이라 부른다.
이를 통해 디코더는 단어를 생성할 때마다 입력된 원문의 정보를 풍부하게 활용할 수 있게 됐다.
트랜스포머
언어 모델의 격변
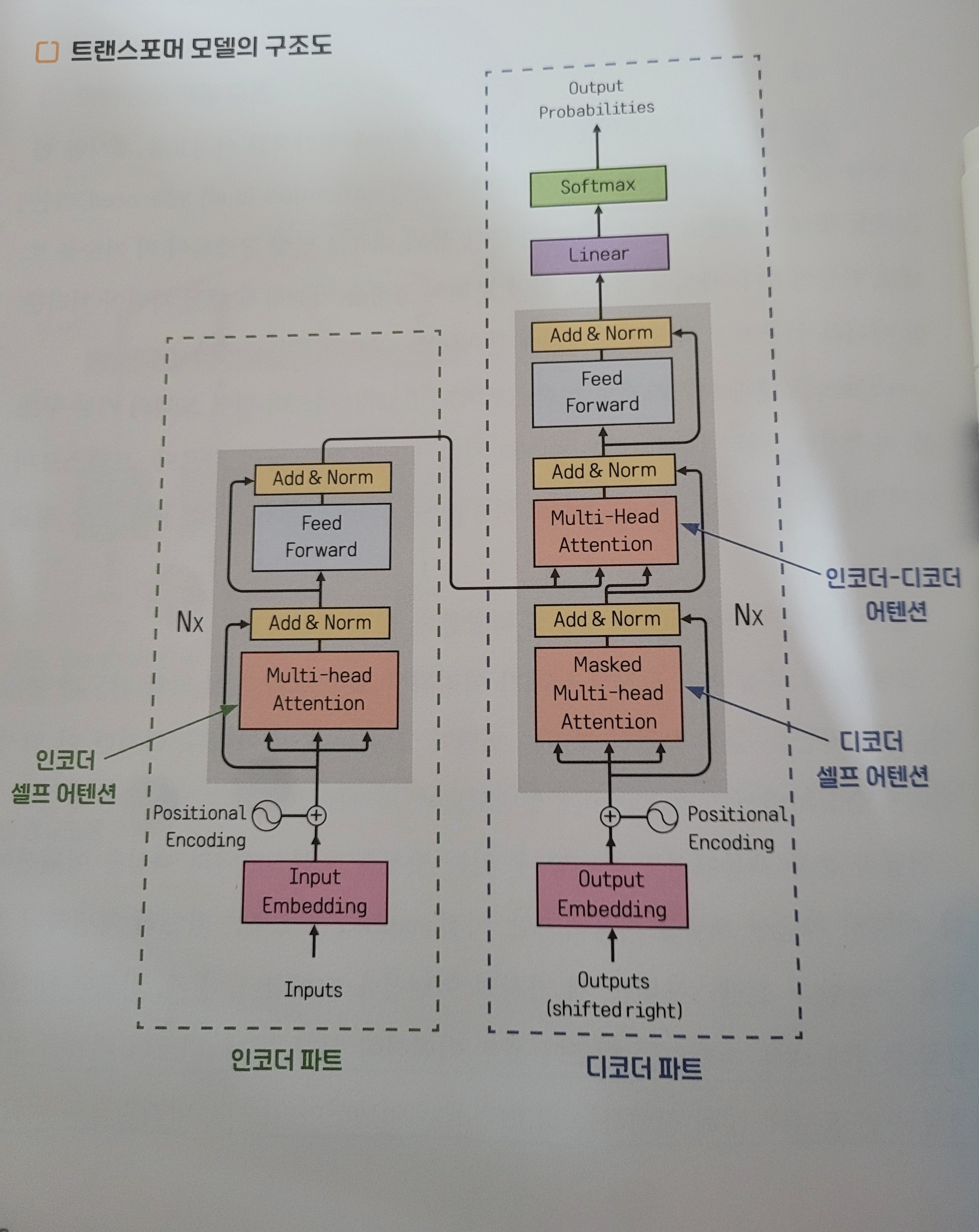
트랜스포머는 세 가지의 어텐션을 수행한다.
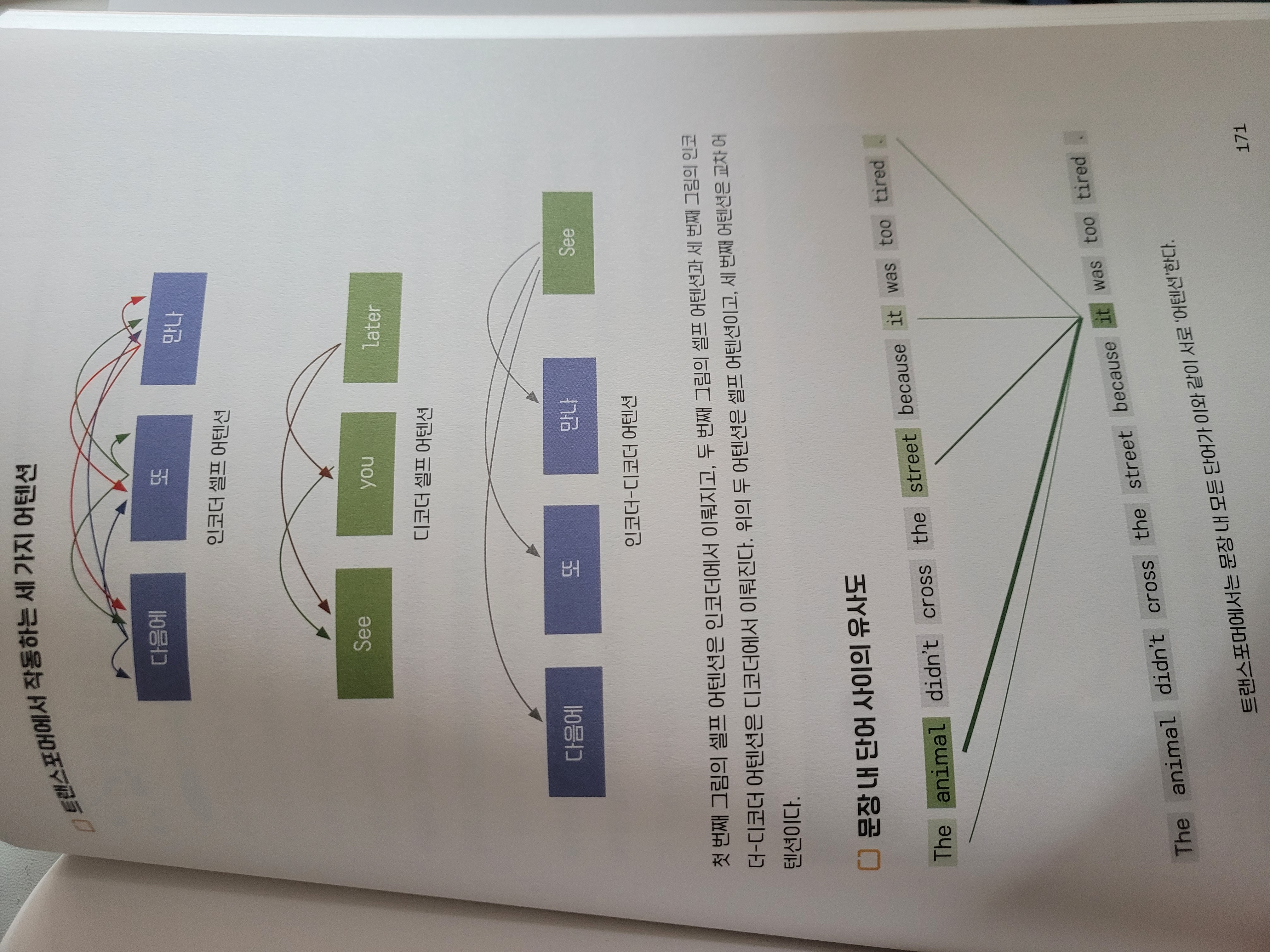
- 인코더 내에서 입력 문장에 대해 진행하는 인코더 셀프 어텐션
- 디코더 내에서 현재 생성 중인 문장에 대해 진행하는 디코더 셀프 어텐션
- 디코더가 다음 단어 생성을 위해 인코더의 입력 문장을 참고하는 인코더-디코더 간 어텐션
1, 2번 어텐션은 인코더가 인코더 자신을, 디코더가 디코더 자신을 들여본다 해서 셀프 어텐션이라 부르고, 3번째 어텐션은 인코더-디코더 어텐션과 같은 개념이다.
인코더 셀프 어텐션
- 입력된 문장 내 단어들끼리 서로의 관계성을 보는 것인데, 각 단어들이 갖는 임베딩 정보를 활용해 문장 내 모든 단어들에 대해 상호 유사성을 계산하다.
- 이후 이 계산된 정보를 각 단어의 임베딩값에 다시 반영해 새롭게 갱신한다.
- 이 과정을 거치면 각 단어의 임베딩값은 문장 전체의 특성 정보를 충분히 반영한 임베딩값으로 특화된다.
디코더 내 셀프 어텐션
- 인코더 셀프 어텐션과 마찬가지로 문장 생성을 위해 디코더가 현재까지 생성한 단어 열을 대상으로 디코더 내에서도 진행하는 것이다.
- 현재까지 생성된 단어 열 안에서 각 단어 사이의 관계 정보를 정확하게 파악하는 것은 적절한 다음 단어를 예측하는 데 큰 도움이 된다.
인코더-디코더 어텐션
- 디코더가 다음 단어를 생성할 때마다 인코더의 모든 단어를 어텐션하는 것
트랜스포머는 이렇게 만들어진 인코더, 디코더를 각각 여러 층으로 쌓아 성능을 더욱 높인다.
하지만 트랜스포머는 RNN을 사용하지 않기 때문에 각 단어의 문장 내 순서 정보를 해당 단어의 임베딩값에 별도로 추가해서 모델이 문장 내 단어들의 순서를 인지할 수 있게 해준다.
트랜스포머 메커니즘의 특징
트랜스포머의 학습
트랜스포머에서는 어텐션이 학습된다.
각 어텐션 내에서 배치된 가중치들이 학습된다.
각 어텐션을 연결하는 연결 모듈, 임베딩 등 모델을 구성하는 요소들의 가중치들이 학습된다.
RNN 대신 어텐션을 학습 모듈로 사용하는 방법은 학습 과정을 병렬화해서 학습 시간을 단축하는 장점도 있다.
트랜스포머의 메커니즘 :
문장 내 단어 사이의 상호 관계성을 확인해 각 단어의 임베딩값들이 문장의 특성 정보를 충분히 반영한 임베딩 값으로 특화된다는 점
워딩 임베딩 과정을 통해 각 단어 단위로 특화된 정보가 문장 전체를 보면서 다시 한 번 특화된다.
BERT와 GPT
트랜스포머로 만든 대표적 언어 모델
BERT
- 트랜스포머에서 인코더를 사용한 모델이다.
- 문장의 특성을 이해하는데 방점을 두고 있다.
- 주어진 문장 가운데 일부를 가리고 수행하는 빈칸 맞히기 형태의 학습과 다음 문장 예측하기로 학습된 모델이다.
- 문장이나 문서의 성격 분류, 두 문장 사이의 관계 분류, 개체명 인식 등 문장 전체의 맥락에 대한 이해가 중요한 일에 두루 쓰인다.
GPT
- 트랜스포머에서 디코더를 사용한 모델이다.
- 매끄러운 문장을 잘 생성하는 데에 방점을 두고 있다.
- 다음 단어 예측하기로 학습된 모델이다.
- 문장을 생성하거나, 대화를 주고받는 형태의 일에 주로 쓰인다.
BERT와 GPT의 출력
BERT
- 주어진 문장을 단어 단위의 임베딩으로 인코딩하는 모델
- 입력 문장은 단어들로 나뉘어져 입력되고, 입력된 단어들은 BERT를 통해 임베딩 벡터로 출력된다.
- 즉, 문장 전체의 맥락과 의미 관계 등을 고려해 ‘컨텍스트화된’ 단어 수준 임베딩, 문장의 특성을 담은 워드 임베딩
GPT
- 문장을 왼쪽에서 오른쪽으로 생성하는 언어 모델로, 이전 단어들을 입력받아 다음 단어를 예측하는 방식으로 작동한다.
- 출력은 어떤 단어가 다음 단어로 가장 적절한지에 대한 확률값이다.
- 즉, 다음 단어의 확률값
고성능 언어 모델의 비결
- 트랜스포머
- 언어 모델이 입력된 문장을 왜곡 없이 정확하고 정교하게 분석해 수치화할 수 있도록 함
- 학습에 사용된 어마어마한 데이터 양
- BERT는 33 억개의 단어, GPT-3은 570GB의 텍스트 데이터를 학습에 사용하는 것
- 해당 언어의 전반적인 특징뿐만 아니라, 다양한 세부 특징들까지도 양적으로 폭넓게 학습할 수 있다.
- 어마어마한 규모의 매개변수(가중치) 개수
- BERT는 3억개 이상, GPT-3는 1,750억개
- 머신러닝 모델이 학습할 때 문제의 특성을 최대한 다양한 각도에서 충분히 세밀하게 담아낼 수 있는 여건을 확보할 수 있다.
- 컴퓨팅 자원
- GPT-4는 학습에 1만여 개의 GPU를 사용
- 대규모 전산 처리
기초 원리
대규모 언어 모델도 가중치를 찾는 머신러닝 모델이다.
결국 대규모 언어 모델의 학습도 머신러닝의 기본 가설식 y = wx + b의 학습 원리와 같은 선상에 있다.