인공지능 구조 원리4 - 기초
자연어 처리
사람 말을 컴퓨터로 처리하는 기술
자연어 처리(Natural Language Processing, NLP)는 사람 말을 정제하고 숫자로 변환해, 컴퓨터가 내용 요약, 분류, 번역, 문장 생성, 질의응답 등을 수행할 수 있도록 한다.
- 말과 문장은 단어 단위로 쪼개거나 의미를 가진 더 작은 단위인 형태소로 잘게 쪼갤 수 있다.
- 자연어 처리에서는 이렇게 잘게 쪼갠 하나하나를 토큰(token)이라 부른다.
- 토큰은 일반적으로 사람 말을 컴퓨터로 처리하는 기본 단위다.
사람 말 -> 숫자로 변환
- 토큰들을 쭉 나열해 일련번호를 매긴 후, 실제 문자 대신 이 번호들을 사용해 진행하고, 모든 처리가 완료되면 산출된 결과를 다시 문자로 바꿔 출력한다.
인덱싱 : 토큰들에 일련번호를 매겨주는 작업
어휘 목록 : 토큰들을 나열한 집합
워드 임베딩 : 단어를 각각의 ‘특성이 담긴’ 숫자 체계로 변환하는 작업
- 각 단어의 의미적, 문법적 특성들이 잘 담겨있다.
워드 인베딩이 단어를 표현하는 방법
다차원 공간상의 좌푯값으로 단어를 배치한다.
- ‘차원’ 이라는 속성이 있는데, 이는 단어의 특성을 얼마나 많은 요소로 나눠 표현할지를 결정하는 속성이다.
- 차원이 클수록 단어의 특성을 여러 개의 값으로 나눠서 좀 더 세부적으로 표현할 수 있다.
예를 들어, ‘사과’와 ‘배’ 같은 공통점이 있는 단어들은 서로 가까이 위치하고, ‘달리다’, ‘뛰다’와 같이 의미가 같은 단어들 역시 가까이에 있게 된다.
전이학습
학습의 출발점을 달리하다.
전이학습은 이미 학습이 완료된 머신러닝 모델이 새로운 모델에게 자신의 가중치 설정값을 전수해 주는 것을 말한다.
가중치의 초깃값 설정은 학습의 시작점을 설정하는 일인데, 용도가 빗스한 모델이 학습을 통해 찾아낸 가중치값을 새로 학습시키려는 모델의 초깃값으로 설정하는 것은 좋은 성능을 내는 모델을 쉽게 만드는 방법이다.
파인튜닝(Fine-Tunning) : 원하는 용도로 모델을 특화하려고 추가 학습을 통해 가중치를 미세 조정하는 과정
언어 모델
단어 뒤에 어떤 단어가 오는지를 예측한다.
현재까지의 단어 열 구성을 ㅊ마고해 다음 단어를 예측하는 것이 RNN 기반 언어 모델이다.
학습 방법
- 앞 단어부터 순차적으로 진행
- 뒤에서부터 거꾸로 진행
- 문장 주간의 단어를 감추고 맞히는 식으로 진행

대규모 언어 모델 : 헉숩울 대규모로 진행한 언어 모델
- 학습에 사용한 데이터양이 크다, 가설식이 갖는 변수(가중치)의 개수도 크다, 학습시키기 위해 투입된 컴퓨팅 자원도 크다.
- 언어 체계를 종합적으로 이해하고 각종 자연어 처리에 범용으로 사용할 수 있으며, 주어진 문장을 분석해 수치화하는 모델
- 일반적인 언어 모델은 특정 용도를 정하고 만드는 반면, 대규모 언어 모델은 언어 자체를 이해하도록 학습시키기 떄문에 각종 자연어 처리에 다용도로 사용할 수 있다.
인코더-디코더 모델
데이터 열을 입력받고 대응되는 데이터 열을 출력한다.
인코도-디코더 모델 : 문장, 이미지, 음석 같은 다양한 형식의 ‘데이터 열’을 입력받고 대응되는 ‘데이터 열’을 출력하는 모델
인코더 : 사용자가 입력한 문장을 분석해 컴퓨터가 이해할 수 있는 숫자 체계 (임베딩으로 변환하는 모듈)
디코더 : 입력 정보에 상응하는 출력 문장을 생성하는 모듈
Sequencce-to-Sequence(seq2seq) : RNN 기술을 기반으로 구현된 인코더-디코더 모델
- 인코더의 역할 : 입력받은 문장 내 앞뒤 단어들 사이의 관계적 특성을 담아, 해당 문장을 하나의 임베딩값으로 변환하는 것
- 디코더의 역할 : 인코더로부터 전달받은 임베딩값이 담고 있는 정보, 입력 문장이 갖고 있는 의미와 여러 특성에 가장 충실한 출력 문장을 대상 언어로 생성하는 것
컨텍스트 벡터 : 인코딩의 결과 값으로, 좌표값은 입력 문장의 문맥 정보를 담고 있다.
- 디코더의 입력값이 돼 번역할 대상 언어의 문장을 생성하는 재료가 된다.
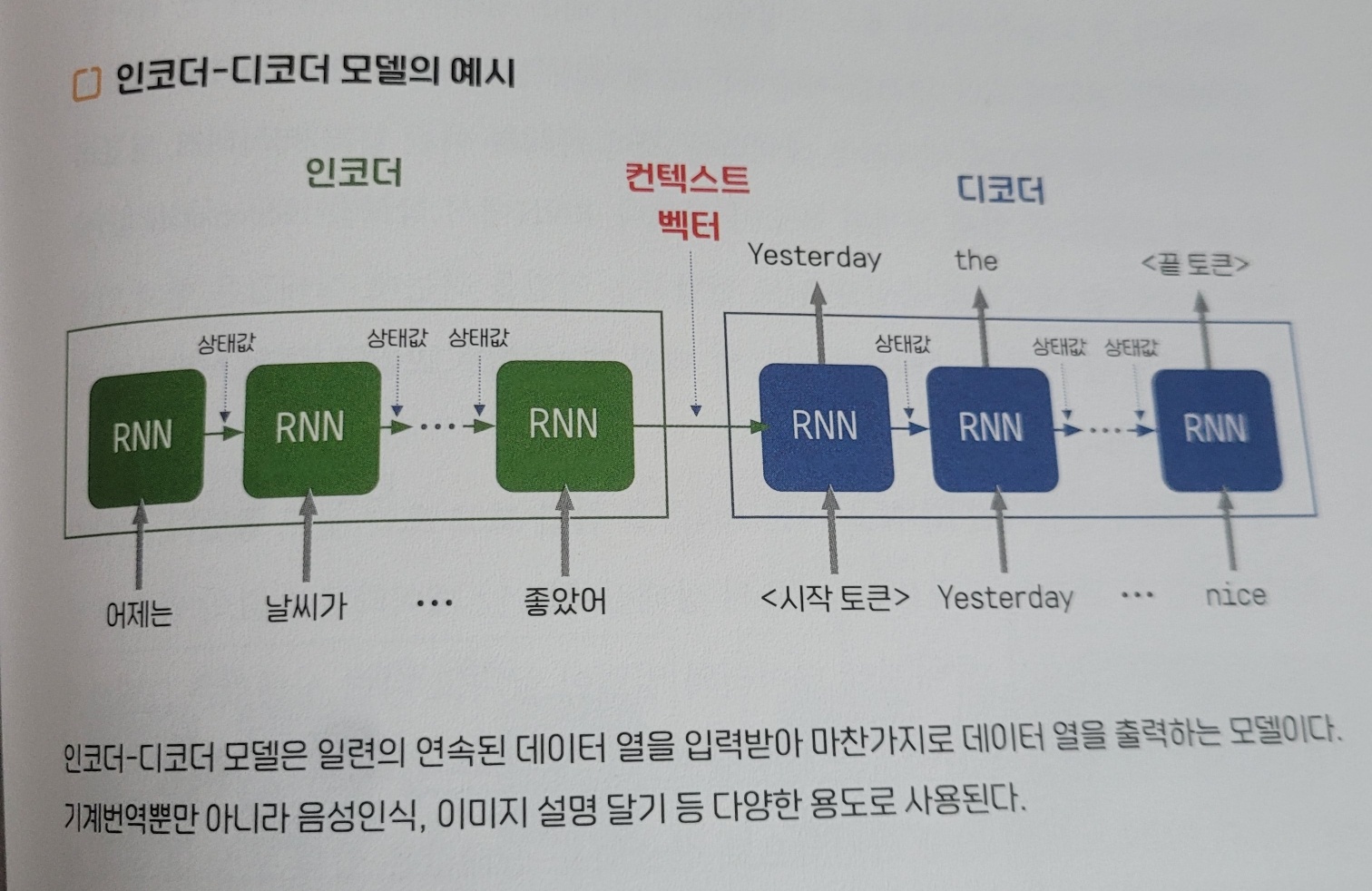
- 인코더 RNN의 목표 : 다음 단얼르 잘 예측하는 것이 아니라 주어진 문장의 특성을 잘 담은 컨텍스트 벡터를 산출하는 것
- 각 시점마다 단어 출력은 하지 않고 상태값만 계속 갱신해 다음 시점으로 전달한다.
- 다코더 RNN의 목표 : 컨텍스트 벡터를 재료로 정답에 가장 가깡누 번역 문장을 생성하는 것
EX) 한국어-영어 번역 모델
- 번역할 한국어 문장을 입력 데이터로 받는다.
- 인코더는 입력 문장을 잘 표현하는 컨텍스트 벡터를 산출하도록
- 디코더는 인코더로부터 받은 컨텍스트 벡터를 활용해 정답에 가까운 영어 문장을 잘 생성하도록 각각의 가중치를 수정한다.