인공지능 구조 원리3 - 기초
CNN(Convolutional Neural Network)
이미지 인식의 대표 모델
이미지로부터 의미 있는 정보를 추출하는 기술인 컴퓨터 비전 분야의 대표적 모델
- ex) 개와 고양이 사진을 구분하는 인공지능
CNN의 학습 방법
CNN은 학습해야 할 가중치를 ‘가로세로 넓이는 갖는 하나의 작은 면 형태의 세트’로 구성한다. 이걸 가중치 집합으로 본다. 가중치 집합을 CNN에서는 필터라 부르는데, 이 필터가 주어진 이미지를 스캐닝해서 각 화소가 갖는 특성을 주변 화소돌의 특성과 함께 학습한다.
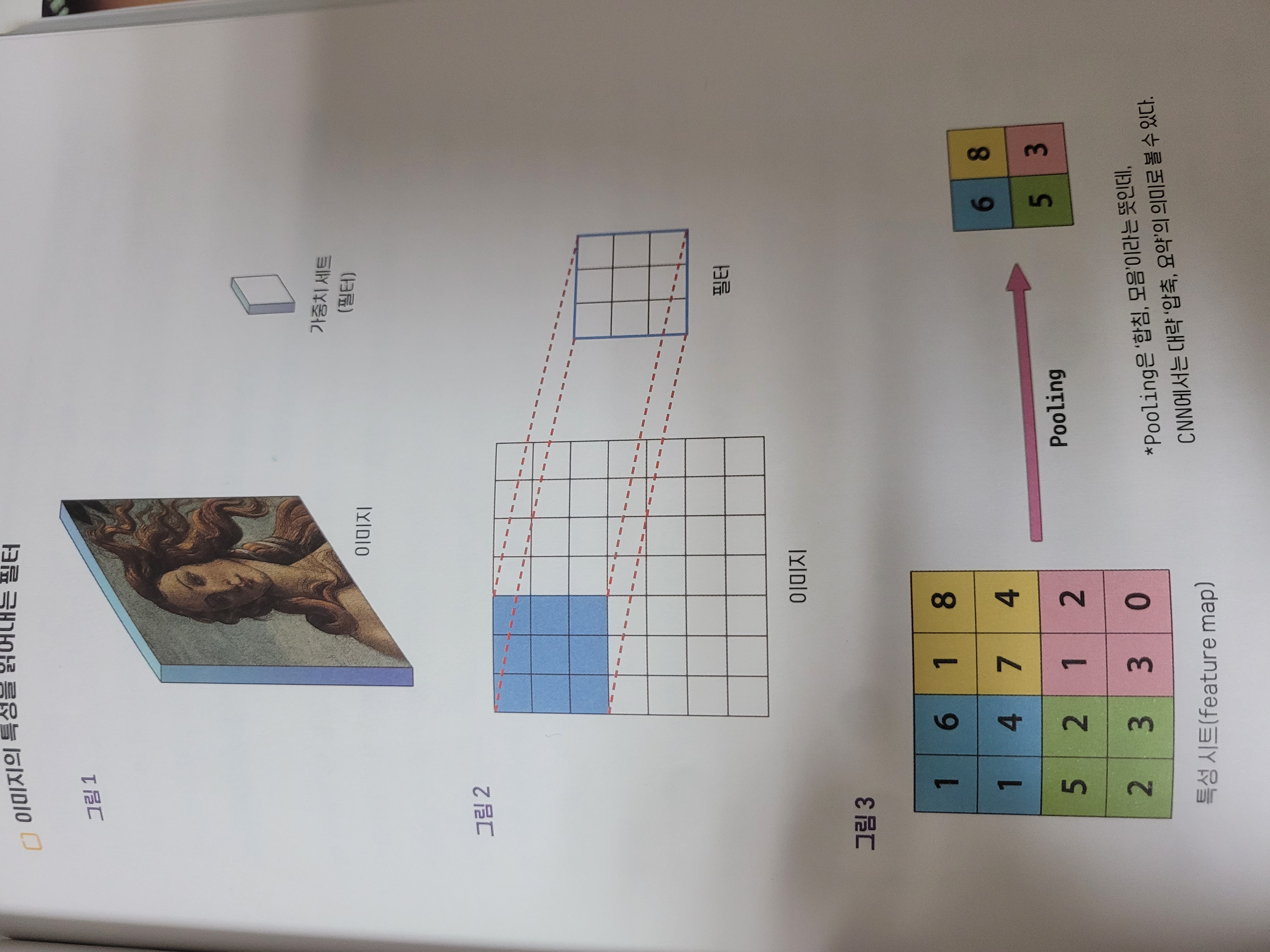
- 그림2에서는 3X3 크기의 필터로 스캐닝하고, 필터의 칸 수가 9개이므로, 가운데 화소를 중심으로 주변 8개 화소들의 특성이 하나의 특성값으로 만들어진다.
- 필터가 읽어낸 특성값들을 나열하면 이 역시 다시 하나의 시트가 된다.
- 이렇게 픽셀을 하나로 묶어 그중 가장 큰 값을 취하는 방법으로 정보를 압축하거나, 아니면 또다시 필터를 적용해 특성을 읽어내는 행위를 반복하면 결국 마지막에는 하나의 숫자 하나가 된다.
- 이렇게 만들어지는 숫자는 주어진 이미지를 정의하는 특성값으로 사용할 수 있다.
그럼 필터는 어떻게 학습되는 걸까?
- 필터의 모든 칸에는 각각 가중치가 들어 있다.
- 즉, 필터의 수식은 H(x)=w1x1 + w2x2 + w3x3 + … + w9x9 이 된다.
- 따라서 선형회귀 모델처럼 CNN 모델도 주어진 이미지가 무엇인지 잘 맞힐 때까지 이미지 데이터를 읽으면서 필터의 가중치값들이 계속 수정된다.
RNN(Recurrent Neural Network)
연속성이 있는 데이터에 특화된 모델
앞뒤 데이터 사이에 연관성이 있는 데이터, 시간적 또는 공간적 연속성을 갖는 데이터와 같이 ‘이전 데이터가 다음 데이터에 영향을 주는’ 데이터세트에 적합한 모델
- ex) 일별 시세 데이터, 주식 시세, 날씨의 기온 정보, 글자가 연속되는 단어나 문장 데이터
- 동해물과 -> 백두산이
앞뒤 데이터 사이에 연관성이 있는 데이터세트를 학습해, 그 연관성을 고려한 예측을 수행하는 모델
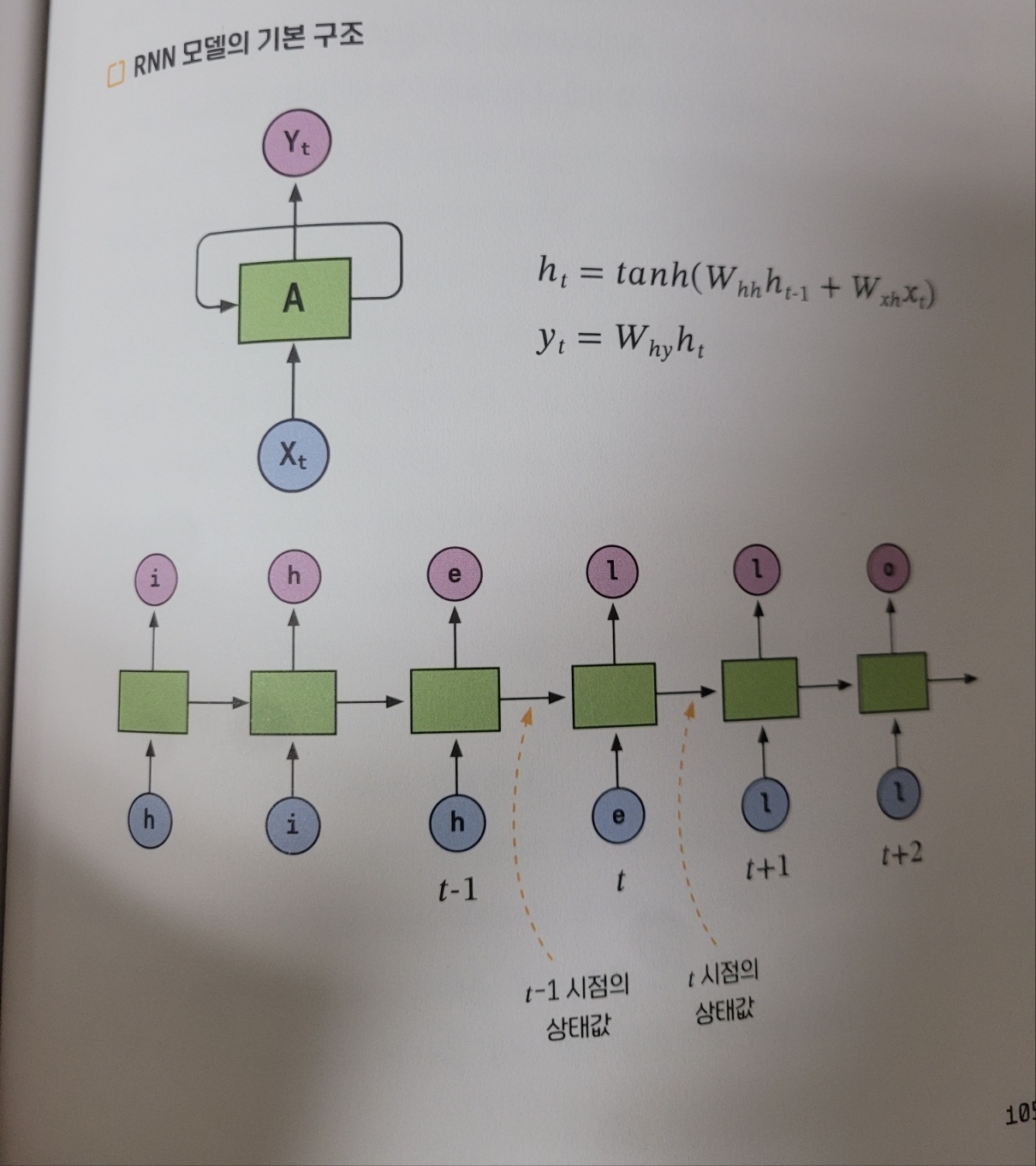
- 현재 모듈이 데이터 ‘e’를 입력받을 차례라고 가정하고 현재 시점을 t라고 하자.
- 시점 t를 기준으로 RNN 모듈은 ‘e’라는 데이터와 함께 시점 t-1에서 생성된 상태 값도 함께 전달받는다.
- 이 두 가지 입력 데이터를 활용해 시점 t의 출력값 ‘l’을 예측하고, 마찬가지로 그 두 데이터를 토대로 모듈의 상태값도 새롭게 갱신하다.
- 갱신된 상태값은 시점 t+1로 전달돼 다음 출력값 ‘l’을 예측하는데 데이터로 활용된다.
RNN은 트랜스포머, BERT, GPT와 같은 대규모 언어 모델들의 할아버지 격인 모델이기도 하다.
지도학습
소위 ‘레이블’이 있는 데이터세트를 이용해 컴퓨터가 문제와 답을 같이 보면서 학습하는 방법
- 선형회귀, 이진분류, 다중분류, CNN, RNN 등
RNN은 왜 지도학습인가?
- 수천, 수만 자의 글자가 들어 있는 문장 데이터를 제공받아 학습한다.
- 다음 글자를 예측하는 모델에 주어진 문장 데이터에는 이미 레이블이 들어 있다.
- 현재 글자의 다음 글자가 레이블이다.
- ex) “안녕하세요” ‘하’ 데이터의 레이블은 ‘세’ , ‘세’ 데이터의 레이블은 ‘요’가 된다.
- 언어 학습용 문장 데이터는 학습 데이터를 만들기 위해 사람이 일일이 딱지를 달아주지 않아도 된다는 특징이 있다.
- 따라서 다음 글자나 단어 등을 예측하는 모델들의 문장 데이터 학습 방법을 자기 지도학습이라 부른다.
비지도학습
별도의 레이블 정보가 없이, 정답이 따로 제공되지 않는 데이터로부터 컴퓨터가 스스로 학습하는 방법
- 데이터세트에서 데이터들 사이에 존재하는 관계성이나 유사도에 따라 데이터를 자동으로 그룹화하는 군집분석이 대표적이다.
K-means
주어진 데이터를 분석해 특성이 유사한 데이터들을 자동으로 그룹화하는 알고리즘 ex) 고객 유형 분류, 데이터의 이상치 탐지, 문서 분류 등
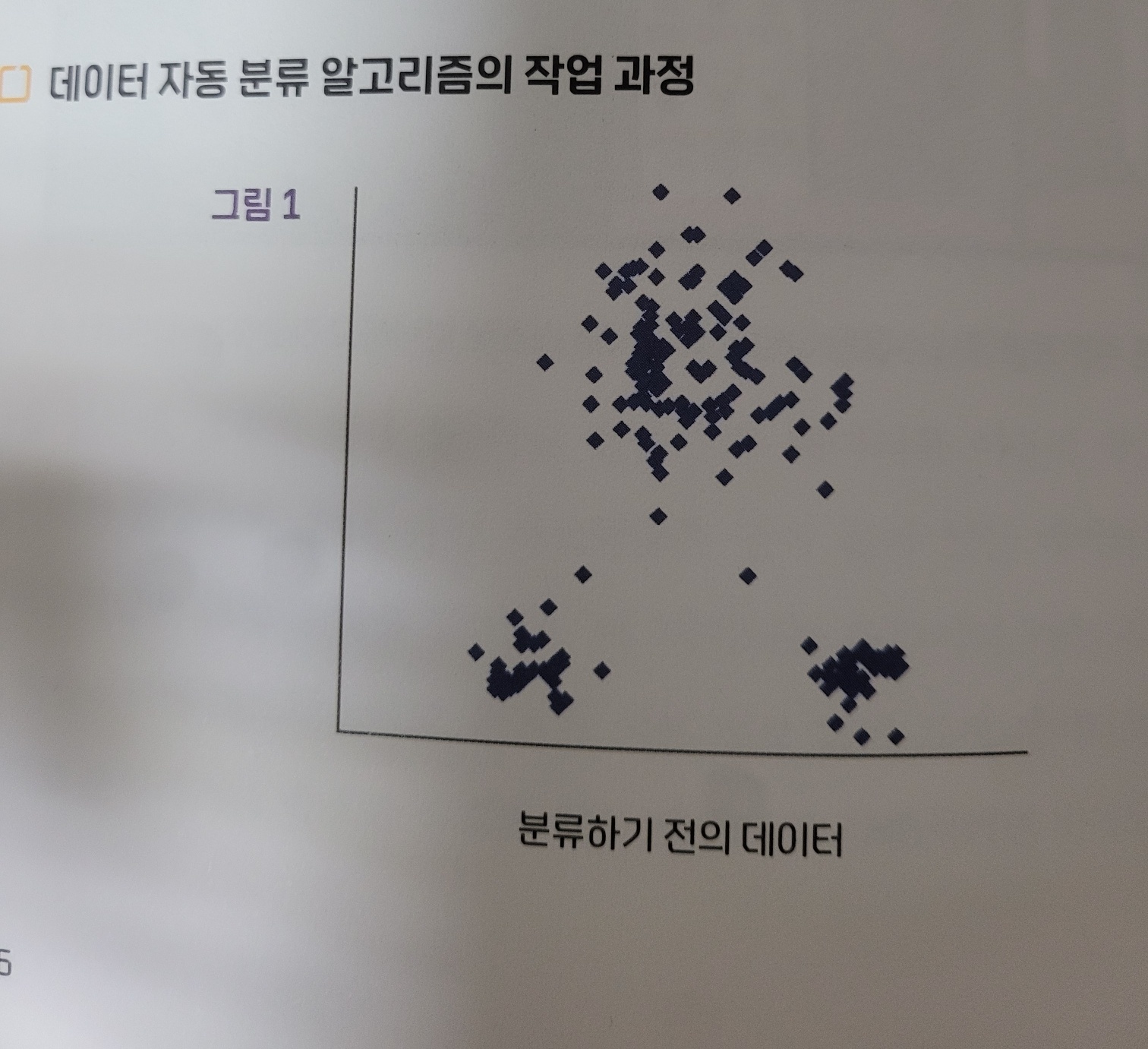
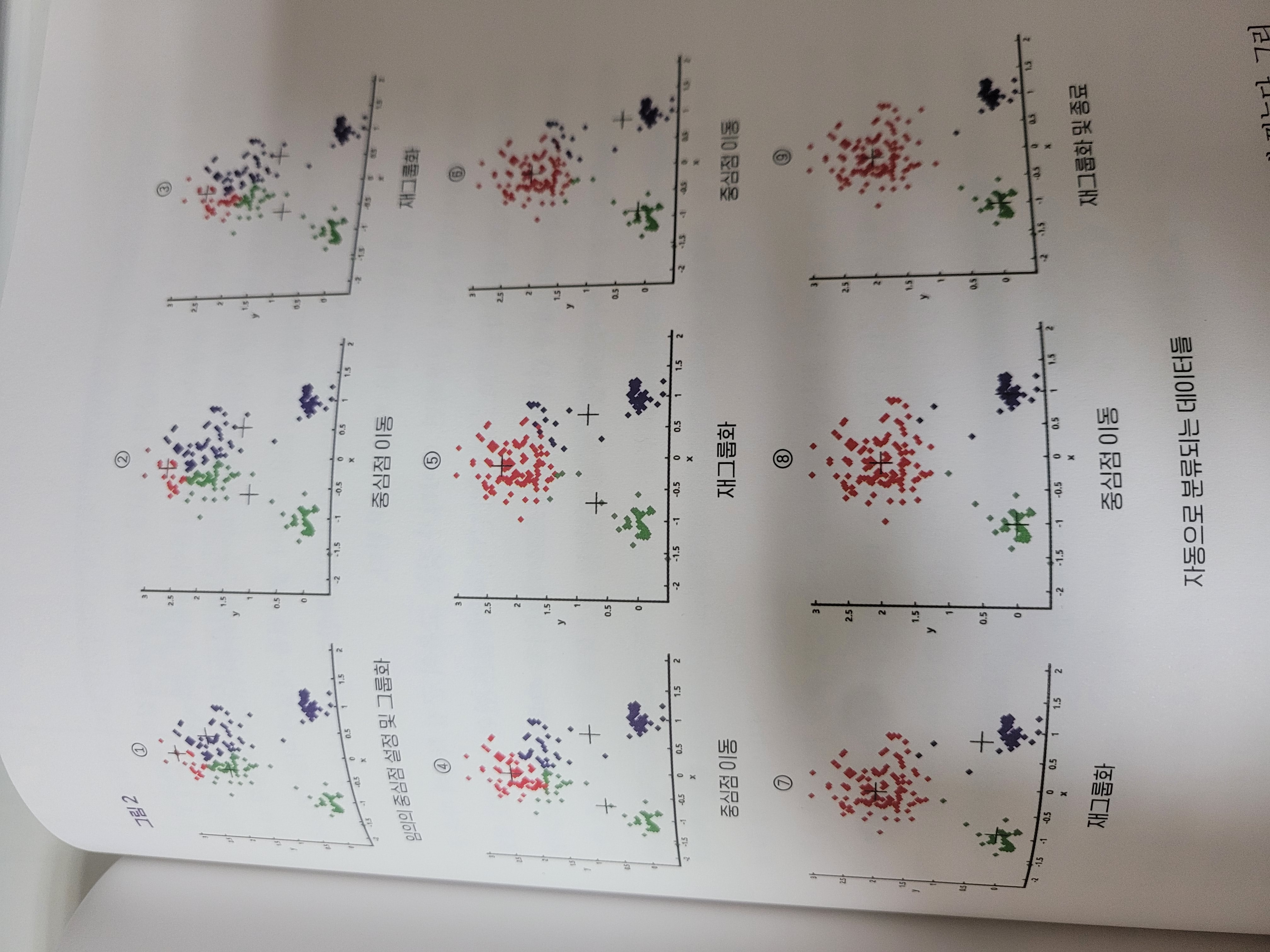
- 먼저 그래프상에 각 그룹의 중심점으로 사용할 점들을 임의로 몇 개 찍는다.
- 그리고 각 개별 ㄷ레이터 입장에서 이 중심점들 중 ㅓ리가 가장 가까운 점을 찾아서 이를 자신의 중심점으로 삼도록 한다.
- 만들어진 각 그룹별로 그룹 내 데이터들의 평균값을 구해서 이 평균값의 좌표를 해당 그룹의 새로운 중심점으로 설정한다.
- 재그룹화 -> 중심 좌표가 크게 변동되지 않을 떄까지 반복
인위적인 지도 정보를 주지 않은 상태(비지도)에서 컴퓨터가 자동으로 데이터를 그룹화하는 기법
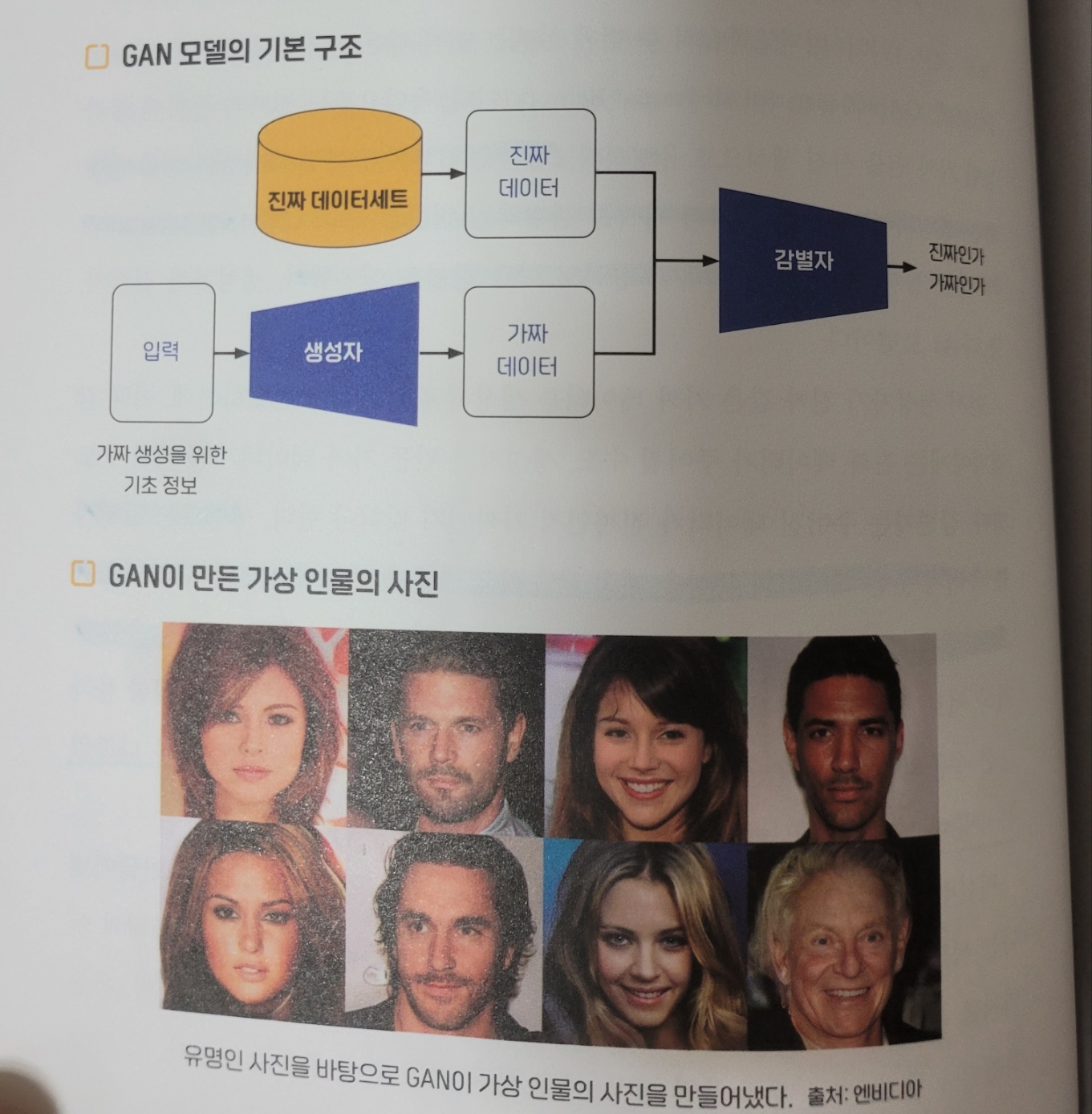
GAN
육안으로는 진짜와 구분이 불가능한 가짜 인물 사진 생성 모델
진짜와 유사한 가짜 데이터를 생성하는 생성자(generator), 진짜와 가짜를 판별하는 역할을 하는 감별자(discriminator)가 서로 경쟁하도록 하는 독특한 방식의 학습 방법
- 생성자가 진짜 같은 가짜 데이터를 생성해 감별자에게 전달하는데, 이떄 감별자에게는 진짜 데이터가 주어질 수도, 생성자가 만든 가짜 데이터가 주어질 수도 있다.
- 감별자는 주어진 데이터가 진짜인지 가짜인지 맞혀야 한다.
- 생성자는 감별자를 속이지 못한 데이터의 특성을 계속 학습해 감별자가 맞히기 어렵게 계속 발전하고, 감별자 또한 생성자가 만든 가짜의 특성을 계속 학습해서 판별 능력을 올린다.
생성자는 진짜와 가짜의 구분이 사실상 불가능한 수준의 산출물을 만들고, 감별자가 맞히는 확률이 50%, 즉, 찍는거나 다름없는 수준이 된면 학습은 마무리된다.
강화학습
학습 데이터 없이 시행착오를 통해 컴퓨터가 학습하는 방법
- 일단 그냥 부딪혀보면서 될 때까지 학습하는 식의 접근 방법
- ex) 로봇이 행한 동작과 관련해서 지속적인 피드백을 주면, 시행착오를 통해 주어진 일에 좀 더 숙달되고 능숙해진다.
- 제한된 환경과 단순한 작동 규칙이라는 조건하에서는 학습 성능이 막강하다.